
Storing every webpage on the internet, books, movies, audio and software digitally and then making it available to everyone is s a challenging task is an understatement. However, that’s what the San Francisco based non-profit the Internet Archive is doing since it was founded. And that, for the record, was in 1996 by Brewster Kahle, after he had sold 2 successful companies: WAIS Inc to AOL in 1995 and Alexa Internet (yup that Alexa) to Amazon in 1996.
Head over to www.archive.org and you can access this library. When it was first founded it only stored a few webpages. Today it has 1,876,584 movies, 2,310,628 audio recordings, 7,481,674 texts from various books. It also has one of the greatest collections of classic software on the planet. As impressive as they are, all of them pale in comparison to the infamous Wayback Machine.
In case you’re lost: the Wayback Machine is the initiative by the Internet Archive to save webpages and ultimately archive the ENTIRE internet from 1996. In other words, the Wayback Machine is an (awesome) internet time machine.
At the time of writing, the Wayback Machine has 452 BILLION webpages saved. Want to see Microsoft.com back in it’s original form in 1996? No problem! Want to know what Google looked like in August 2003? Here’s your answer!
Why is it doing this? Because its mission, they say, is to build the greatest library on Earth.
How does the WayBack Machine work?
To use the WayBack Machine, simply head over to www.archive.org/web. Then enter the website you want to see in the search bar and press enter.
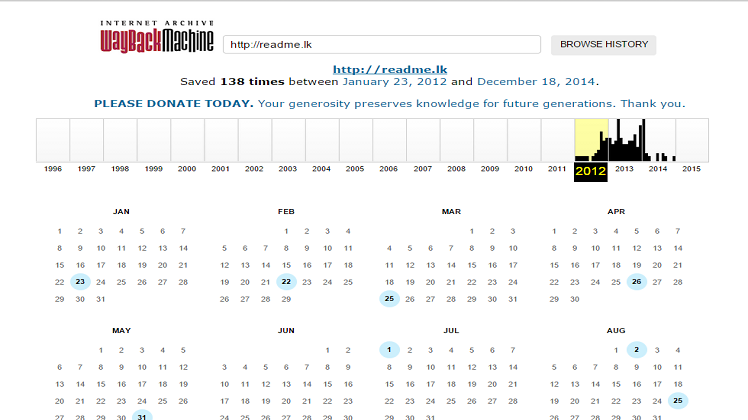
You should then be greeted with a calendar like the one shown below. Click on one of the dates highlighted within a blue circle to view a snapshot of what the website looked like on that particular day. To go further back in time, click on a year in the menu on top which has a black bar.
What happens underneath?
When it comes to dealing with books, videos, audio recordings and software, the Internet Archive does the process of digitizing and adding them to the library manually. When it comes to collecting web pages for the Wayback Machine, things are different. While the option for anyone to upload webpages exists, most of the work is done with web crawlers.
Web crawlers are automated bots that visit a web page. They visit a link, save the resulting web page and the content on it. Once that is done, the crawlers repeat the process all over again for every other link on the web page. Once the website has been saved, the crawlers will revisit it in anywhere between a few weeks to months and grab an updated version of the website. While this is a simple process, it can still take anywhere between 6-14 months after a crawlers visit before a website appears on the Wayback Machine.
There are requirements, though. When it comes to websites, a crawler will only archive it if the site is listed on the Alexa Rankings, not password protected and the site owners have not used the robots exclusion standard. Even if a website meets these requirements, certain content on it may not be archived. This can be due to various reasons – files exceeding the 10MB limit, simply publishers restricting access. Which is why any website archived on the Wayback Machine is considered to be a snapshot.
So how much space does the Wayback Machine need? 9.6 petabytes, as of December 1st 2014. However, as the internet keeps growing at it’s rapid pace, so too does the archive of the Wayback Machine. Currently it’s growing at approximately 20TB each WEEK. That’s like downloading TWENTY THOUSAND 1080p movies every week!

All this data is stored in specially designed servers that store 1 Petabyte called the PetaBox (pictured above) across 4 data centres. One data centre is located in San Francisco itself inside the Internet Archive headquarters itself. The other two data centres are located in Redwood City and Richmond. The fourth data centre would be the modern day library of Alexandria which acts as a backup to ensure that the humanity never loses the Internet Archive library like the original library of Alexandria.
Who pays the bills?
It’s probably safe to say that archiving the internet doesn’t come cheap. Even if it’s a non-profit, the Internet Archive still needs money for everything it does. According to Wikipedia, the Internet Archive has an annual budget of $10 million. So where does it get the money from? Like any good library, there’s a variety of sources:
- Brewster Khale’s own money
- Government grants
- Partnerships with private organizations
- Donations
Despite the Internet Archive having ambitious goals, it’s business model seems to be very simple.
Does it serve a purpose?
The average Joe may never use the Wayback Machine, except maybe once or twice to satisfy his curiosity by looking at how his favourite websites were like back in the day. However, the average joe was never the target market to begin with! The main users of the WayBack Machine and the Internet Archive in general are: researchers, historians, scholars.
Furthermore, the WayBack machine is just like any other museum or library preserving our history. Take one look at the modern era and you’ll find that a lot of our culture and records of important events are all stored digitally somewhere on the Internet. However, this doesn’t mean it’ll be there forever – because a webpage lasts for only 77 days on average. The Wayback Machine is the keeper of modern history. History those future generations can learn from so that they don’t repeat our mistakes. Especially the design of, say, the Microsoft website back in the day.

GIPHY App Key not set. Please check settings